
Is your application production ready?
tips and checklist for making sure the application is production-ready and resilient.
Arun tigeraniya
IS YOUR ONLINE APPLICATION PRODUCTION-READY
what is a production-ready application.
We call that service or application production-ready, which can be trusted to work in real-world scenarios and volumes reliably. It should be able to perform without lots of maintenance effort and the least amount of downtime. A production-ready application is operational for longer durations. Hence it must be stable. Creating a production-ready system is much complicated than creating a proof of concept running application. It is easier than ever to get a server from cloud providers and deploy the application on the cloud server. It takes more effort to make sure we are in total control of the application. We must check if we will get notified about when operating conditions are not optimal or when the application is shutting down. These are the basic requirements so that we can take corrective measures. Sometimes we need to churn out applications at blazing speed for showing results. The demo applications have low/nil maintenance requirements, whereas production-ready applications must be very maintainable. An ill-maintained application, small or big, can cause monetary loss, bring a bad reputation directly or indirectly. If we check small pointers while developing and deploying, we can stop many issues from happening in the future. So from our past experiences, we have created the below checklist that can help you in coding & deploying services in a better way.
CHECKLIST
1. External dependecies should be noted down in software itself.
Almost all languages give access to package managers for storing information about external libraries used. NPM, yarn, pip, pip-tools etc should be used to store package information. But requirements mean more than just libary modules. If so those requirements should also be noted and maintained.
2. Deployments should be possible from a single command.
An application that gets deployed easily progresses at a faster pace. Manual work in deployment means there is far more possibility of missing artifacts for deployment. It makes it hard to change the deployment process, add new services to the current infrastructure. It is easy to forget something with the manual setup. Someone will forget something required for correct deployment and will result in downtime or errors later. After 2-3 years, when original developers have left, new developers will fear developing on top of the old stack. When all infra and setup get captured in the deployment routine, these issues are resolved to a large extent.
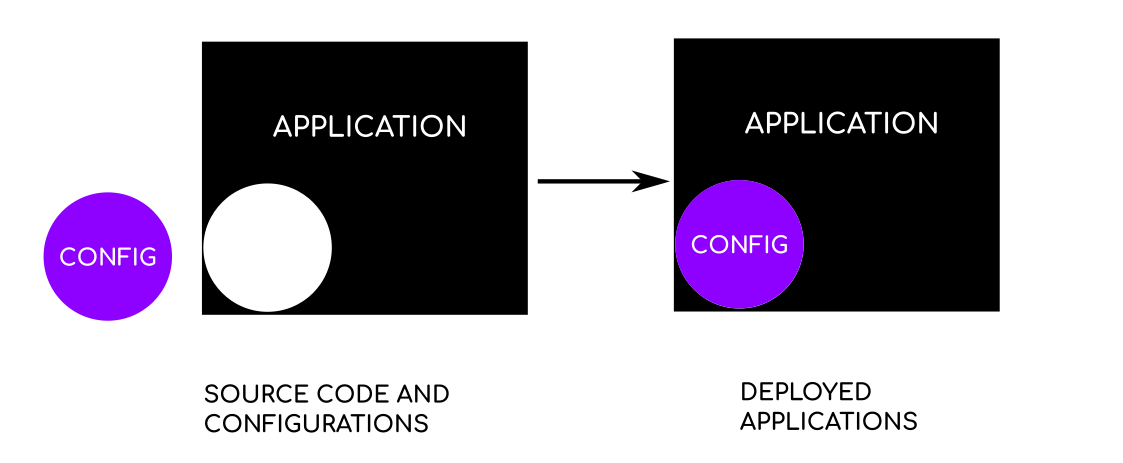
3. Deployment routines should be able to change all configurations/configs required for the system.
What we mean by configuration here is not the configuration required to run the programs. The configuration/constants/definitions which are not code construct may update later. These should reside outside of code. We should be able to change them as required. We have to understand this in more depth to appreciate it better. Suppose a user inputs 1,2,3,4 in the application input and program outputs command result. We can create a mapping inside the program using hash, dictionaries, or use multiple if/else or switch statements. Then we run the function corresponding to the input and return its result. A better structure would be to store a mapping of user inputs to command names as an external file or fetched from somewhere else at runtime. This setup will enable us to configure software easily later. Maybe we would want to run different functions in QA/Test environments etc.
4. Deployment should be repeatable without side effects. Downtime during deployment should be minimal.
Repeat deployment should not adversely affect the current system. Should not perform actions again if not required. For example, if deployment collects all static content to some remote system, it should first check if that step is required. Deploying again on the same network should not delete current firewall rules and create them again. The steps for deployment should be arranged to minimize downtime. We can understand this from an example. Suppose we want to deploy a static website, we can copy all contents on the current hosting folder, and that will update the site. A better approach may be to deploy on a second folder and point the webserver to this new location.
5. Rollback strategy must be ready before deployment.
Inevitable issues happen all the time despite best efforts. In the case of failure, we should be able to revert the application to a previous state. This gets complex for applications with state changes. we should ponder on our strategy for the following items:
- application state. ( user tokens generated, OTPs sent, user sessions ).
- static components changes like media files or static files.
- DB changes. There are many tools, which can help in database migrations. But the developer should also think about data changes and feature rollback.
6. Deployment should enable scaling up/down if required.
Most applications have a peak time for usage. Application code and deployment routine should support scaling up or down. We may not require to scale the system currently. We may only deploy on a single server. But in code, we should not use local dependent features. For example, writing to a file on the server may require changes for code to run from a second server. We may use an adaptor for the current scenario and switch to a second scalable implementation later on. For example, you may store files with a "class FileStorage" that stores file on the local server and later swap with "class CloudFileStorage" that stores files on the cloud. This discussion would require a second article dedicated to it.
- Deployment should enable scaling subparts independently. If the system has multiple parts, those parts should be able to scale independently of each other. This becomes more important in microservices deployments.
7. System functioning should not be dependent on the cloud/3rd party service provider.
Well, this looks counter-intuitive. We cannot create applications nowadays without actually using a cloud provider or 3rd party applications. We send emails, SMS, notifications using other services. Web applications usually get deployed on cloud provider's infrastructure. So what do we mean by this statement? The system should have its view of functionality mapped to an external provider. You can check requirements from 3rd party providers for the functionality and create interfaces for the service. Using the adaptor pattern, we can swap out without changing our main application code. This proxy in between actual business code and 3rd party service can go a long way in the maintenance of the application.
8. Keep services isolated in the system.
We should be able to deploy parts of application independently. Deployment of one service should not affect other services in the system, and when deployed if required other services should get updated as required. This is easily achievable by using docker, kubernetes, lamdba functions etc.
9. Continuous Integration system is not luxury but requirement.
All code changes must run through CI servers, thereby giving team whether application is working or not with new changes. A CI system should do Linting, Testing, security checks and at last actual deployment. usage of CI server automatically takes care of many points discussed above. Jenkins, Buildbot are example of CI systems. You should choose a CI system which suits your application well and your team have familiarity with.
- Versioning information. Application version should increment on each deploy & commit and should be visible from somewhere user can see.
- Deployment Notification. Each time a deployment happens, it should get logged somewhere, and all stakeholders notified. All changes ( source code changes, data changes ) should be logged. This is an important point for keeping evergyone in sync. It also makes everyone a little more responsible to deployments.
- Successfull deployment should be checked for OK report. Response from application post deployment must be checked for correct functionality. This can be manual, but we should strive for making this automated. Also critical piece of software should be make testable in production using dummy accounts or similar strategy where we can check application functionality without actually affecting revenues, analytics.
10. Useful Logging
Logs are critical to application maintainability. Streaming and collecting all logs from different service into a central location is good idea. Ability to create trigger from error logs is also good. A person checking logs should be able to see the reason crash happend and where to check for further details. An error message saying "error happened" is not useful. We must be able to check failure state from logs, metrics, or some other persistent information updated by system. Hence preferably store state changes somewhere. When application boots up, it is good to log its configuration used, but sensitive data should not be logged. Ability to see logs realtime on web or similar interface without logging onto each machine is very useful.
11. Try to use services you can locally develop on, without using internet.
Remote services are very important and easy to use. But easy of use and maintainability should not be confused with each other. If there is no alternative to the service, and that service become unavailable due to any reason, will our application work, is a very important point to consider. If there is no local alternative is available then all developer would need access to that service which may add to the total cost, and should be consider. There are local alternative to cloud services as well, which provide same api, and can be used instead.
12. Make service gracefully shutdown and startup.
A service should also gracefully shutdown. It should stop accepting requests and all requests accepted should preferably be processed.
share this blog within your circle